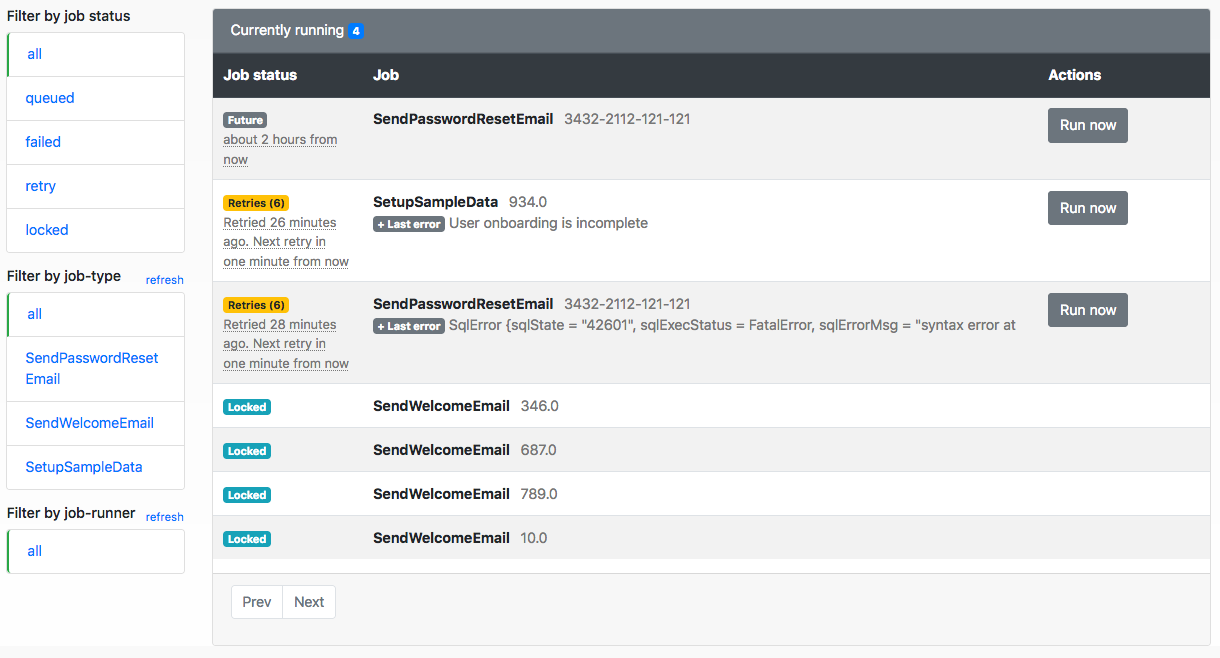
Features
Frequently asked questions
Why build yet another job queue?
Short answer: We couldn't find anything that fit our needs.
Long answer: Read our Utlimate guide on Haskell Job Queues to get an overview of the various packages that solve a similar problem, what works, and what doesn't. It can help you evaluate whether Odd Jobs is the right choice for your needs, or not.
Why is this specific to PostgreSQL? What about Redis?
Since Odd Jobs was built to "scratch our own itch" at Vacation Labs, we picked the datastore that we use in production, i.e. PostgreSQL.
Redis is also a fine data-store for a queue, and we are open to pull-requests that would like to evolve Odd Jobs to work with Redis, or even other RDBMs (eg. MySQL)
Isn't using an RDBMS as a queue a "bad idea"?
Not really. It depends on the ops/sec you expect from your queueing system. PostgreSQL has been used to process 10,000+ jobs per sec. Are your needs more than that? If not, it is strongly recommended to keep your production environment simple, and just use your existing PostgreSQL database as your queueing system.
The pros & cons are discussed at length in this note about storage backends for job-queues.